In Why Developers Love Redpanda, I talked about the exciting developments around WebAssembly and how Vectorized is leveraging the technology to build it’s Intelligent Data API, Redpanda:
WebAssembly, or WASM, is one of the most exciting up-and-coming technologies in software development today. WebAssembly lets developers write code in any major language, translate that code to the compact WASM format, and run it on the web with the high performance of a native application.
Redpanda is one of the first infrastructure technologies to take advantage of WASM, enabling developers to “write and edit code in their favorite programming language to perform one-shot transformations, like guaranteeing GDPR compliance by removing personal information or to provide filtering and simple aggregation functions.”
JavaScript, Python, Rust, Go — anything that compiles to WebAssembly (basically everything at this point) can be used to transform data. Again the key is accessibility — inline WASM transforms in Redpanda represent just that.
Ever since partnering with Vectorized, we at Lightspeed knew that Redpanda was much more than a streaming engine. Redpanda truly is an Intelligent Data API, and it’s Data Policy Engine unlocks one more piece of that puzzle.
Today, I want to expand on this and talk a bit more about the exciting developments coming down the pipe at Vectorized.
Here’s the big idea: rather than ship data to code, which is expensive and latency-prone, why not ship code to the data?
The keystone problem in streaming
Streaming has seen a ton of innovation over the last few years, but one area that remains painful today is stream processing. While a full explanation of these difficulties probably warrants its own article, I’ll cover the most salient points here.
The great thing about streaming is the immutable message queue. The not so good thing about streaming is, also, the immutable message queue.
What do I mean by this? The immutability of the message queue is great because it guarantees that data produced to the topic can be replicated one-to-one by simply consuming the whole queue from the start. This lets you effectively “replay” data like a VHS tape and also gives you built-in auditing, since you know the ordering hasn’t changed. It also decouples producers of data from the consumers of that data, letting the two operate independently without significant coordination work.
However, there are some problems. Immutability not only means you *can* consume the data in the same order it was produced — it means you must (at least as implemented today in the Kafka-API world). Further, immutability means one must consume at least as much as was produced, often many times as much, leading to additional costs in the form of network traffic and other resources. These issues can be avoided to some extent by being very diligent in setting up your architecture a priori, careful in segregating your use cases, etc., but few do this in practice.
In summary, the things that make streaming great also make stream processing complex and difficult.
Shipping code to data
Here’s where WebAssembly comes in. WebAssembly lets us do a small amount of extra compute work to save us a ton of cost in the form of network utilization and latency. Mission critical streams can stay as large as they want without saturating the network.
We’re excited about the power and promise of WebAssembly, and we think it has the potential to do for server-side compute today what JavaScript did for the web in the late 90s. Like JavaScript enabled the shipping of code to the user’s client, WebAssembly lets engineers ship code to the storage engine.
Here’s how.
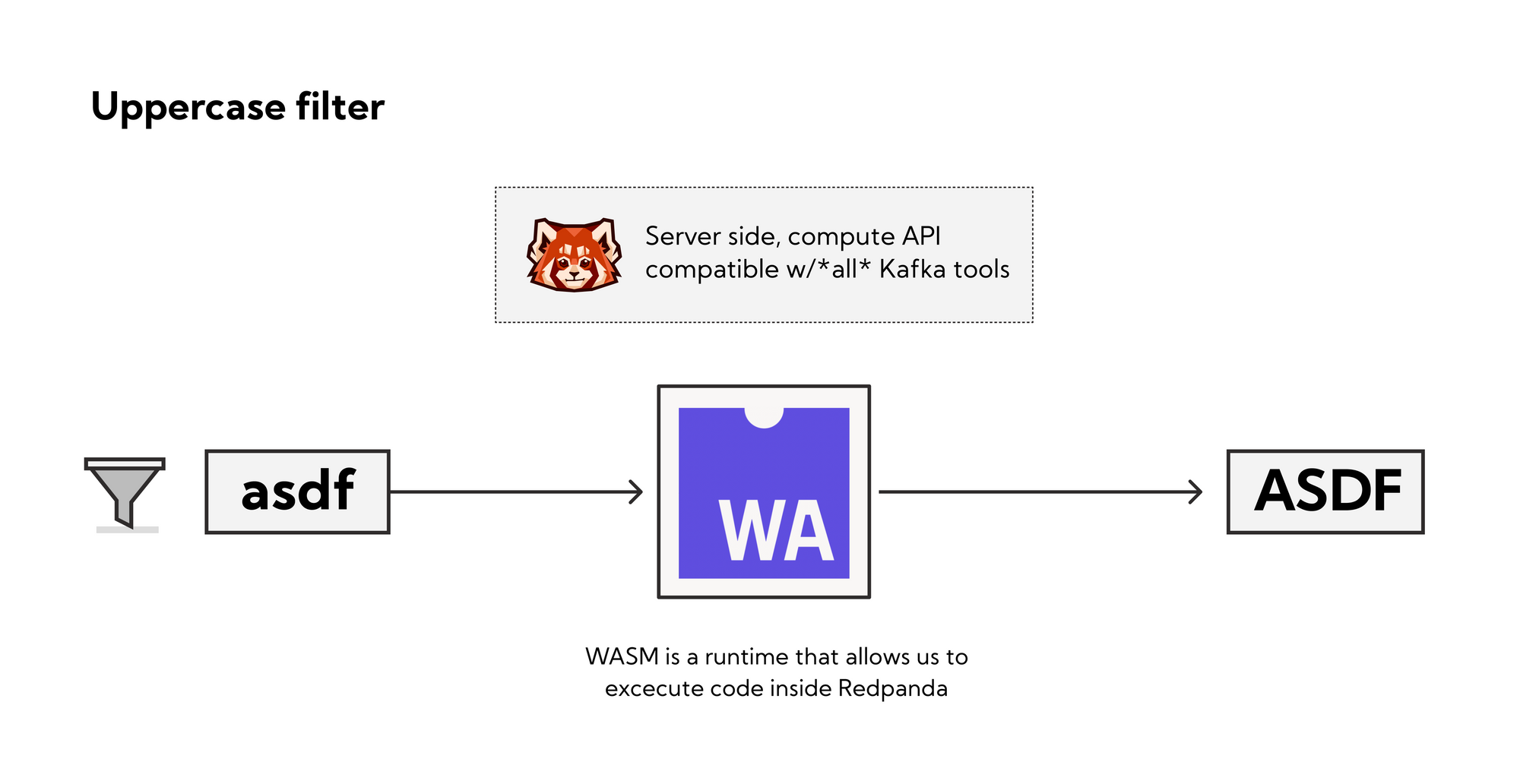
The Redpanda Data Policies Engine simultaneously extends the Kafka API and what you can do with server-side compute. It’s a server-side compute API for Redpanda that’s compatible with all existing Kafka tooling and the broader ecosystem, including Spark Streaming, Kafka Streams, Flink, and more.
With Data Policies, all your favorite tools can benefit from server-side WebAssembly filters, allowing for easy and simple data scrubbing, cleaning, filtering, normalization and more. As a runtime, WebAssembly allows code to execute inside Redpanda, allowing code to be injected into an active cluster at runtime.
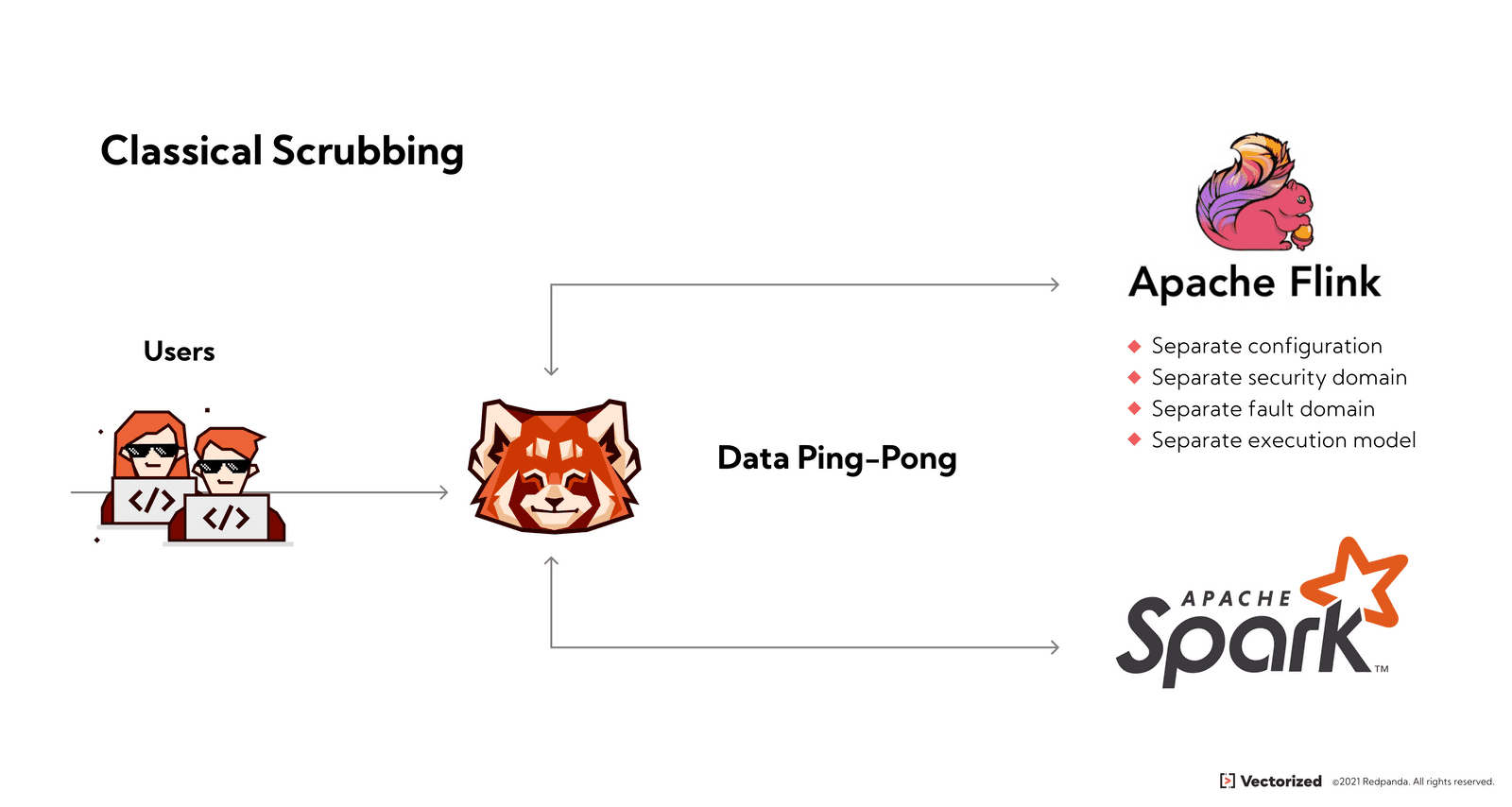
Redpanda Transforms enable extremely low-latency transformations by avoiding the “data ping-pong” that happens in many systems and stream processors today, where data gets sent back and forth between storage and compute, even for very minor operations. Further, Redpanda Transform is built on the V8 engine, the high-performance JavaScript and WebAssembly engine that also powers Chrome and NodeJS.
Transforms in Redpanda are effectively a stateless predicate pushdown. In simple terms, that means performance is massively improved by “pushing down” code to the data, only touching the relevant data (and ignoring the rest), cutting down on wasteful network traffic, I/O, and latency.
Redpanda Transforms are also completely auditable. The controller can report on which specific piece of code is touching which specific piece of data, on which machines, at which topic offsets.
As easy as one, two, THREE
Few things are simple in data engineering, but, as usual, Vectorized is changing the game. For all the cool things happening under the hood, getting started with Data Policies is shockingly easy.
First, write your policy/transform in a WebAssembly compatible language (read: everything). To make this even easier, Redpanda provides native plugins for inline transforms. In the end, you end up with something that looks like fairly standard (JavaScript in this case) code. Here’s a simple proof of concept: transforming all lowercase alphabetic characters in a record to uppercase:
import { InlineTransform } from “@vectorizedio/InlineTransform”;
const transform = new InlineTransform();
transform.topics([{“input”: “lowercase”, “output”: ”uppercase”}]):
…
const uppercase = async (record) => {
const newRecord = {
...record,
value: record.value.map((char) => {
return char.toUpperCase();
}),
};
return newRecord;
}
Next, apply the policy to a Kafka topic. Again this is incredibly straightforward. All it takes is a single terminal command:
> bin/kafka-topics.sh \
— alter — topic my_topic_name \
— config x-data-policy={…}
(redpanda has a tool called `rpk` that is similar to kafka-topics.sh)Now, Redpanda handles the rest.
- Upon a TCP connection to consume from the topic, Redpanda initiates a V8 context
- Bytes are read from disk
- Payload is transformed and re-checksumed (ensures Kafka protocol remains unchanged)
- Redpanda returns the transformed record
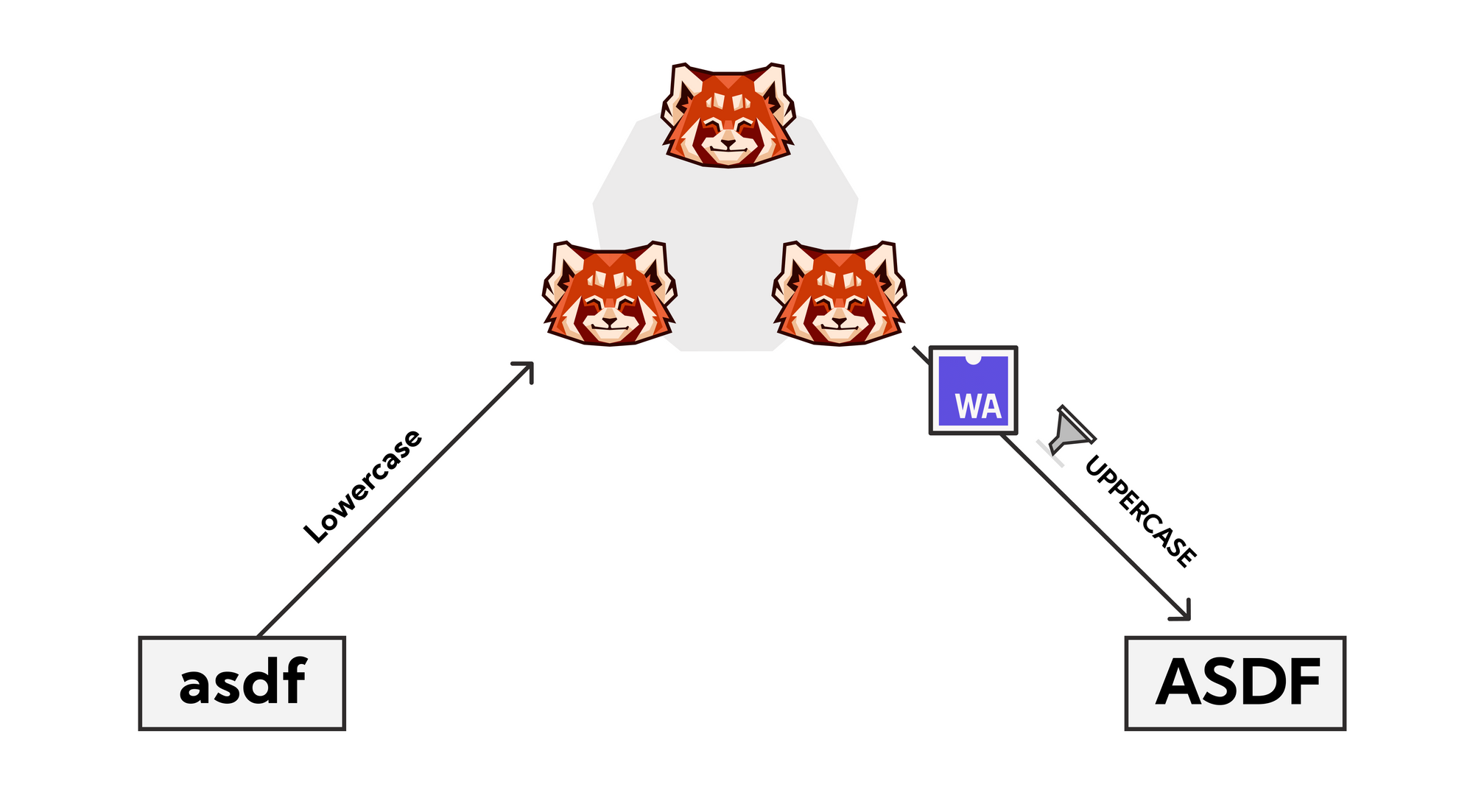
Pretty slick.
Simplicity is the ultimate sophistication
I’ve talked before about Vectorized’s deep understanding and appreciation for the power of simplicity:
Redpanda abstracts away the complexity that often prevents the typical developer from adopting real-time streaming.
The Data Policy Engine continues that tradition.
This was just an example use case, but they only get more interesting from here. GDPR compliance via masking rules. Encryption at-rest, on-disk. All at runtime, with near-native performance.
Curious to learn more after this quick introduction? Alex Gallego, founder of Vectorized, gave a sneak preview of the Data Policy Engine at this year’s Kafka Summit, which you can check out here:
I'm about to show a sneak preview of on the most anticipated features by the community here, as a sponsored talk.
— 🕺💃🤟 Alexander Gallego (@emaxerrno) September 15, 2021
tl;dr - take an *unmodified spark app* and use a push-down predicate in #wasm 🤯🤯🤯
Demo at the end.
#redpanda #kafka #KafkaSummit https://t.co/NiL2SNHrvq